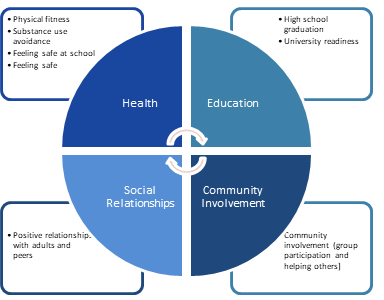
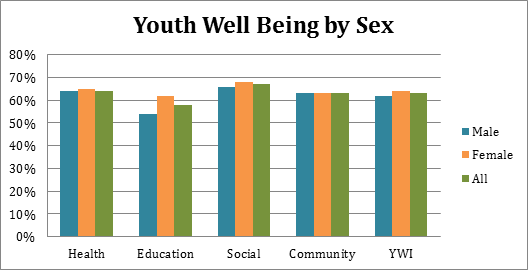
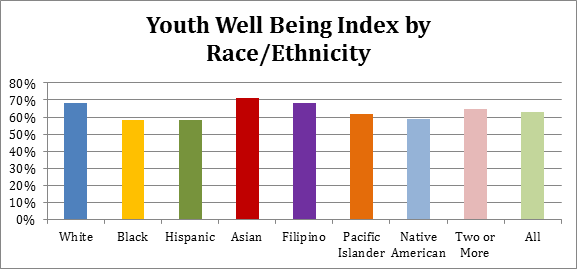
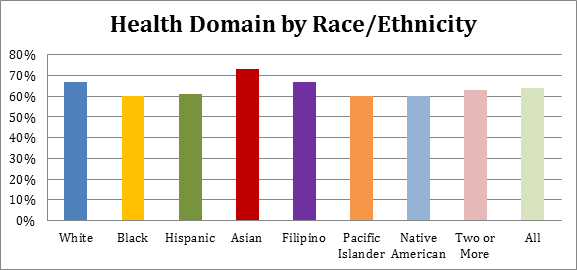
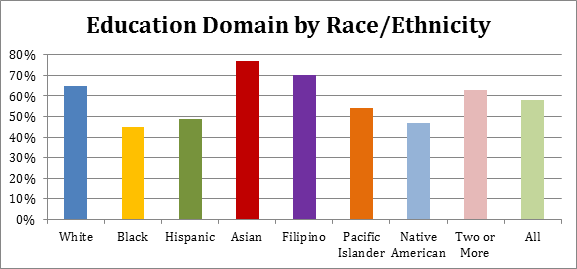
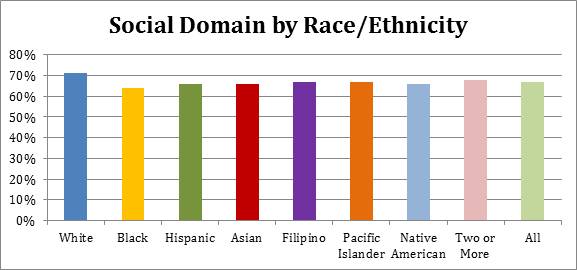
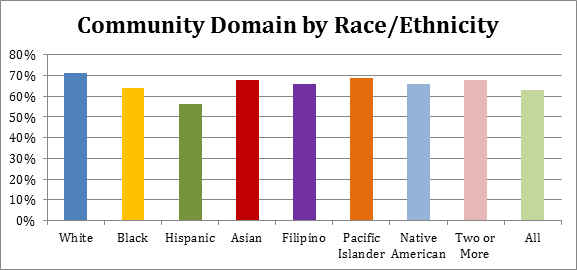
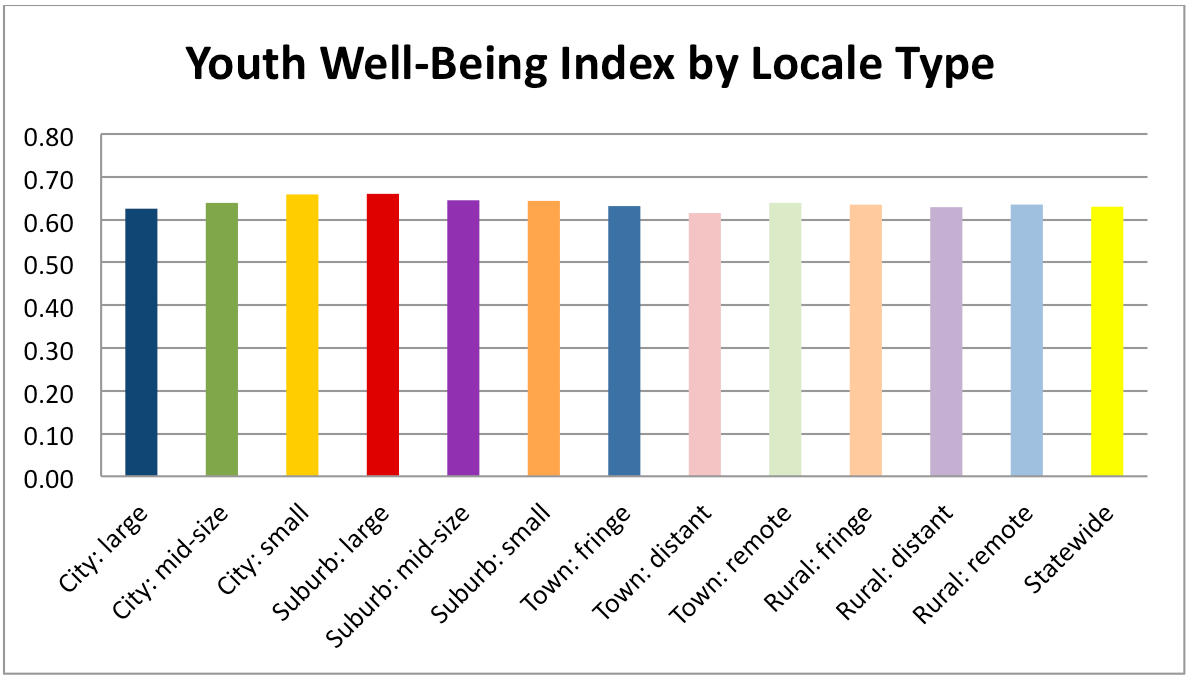
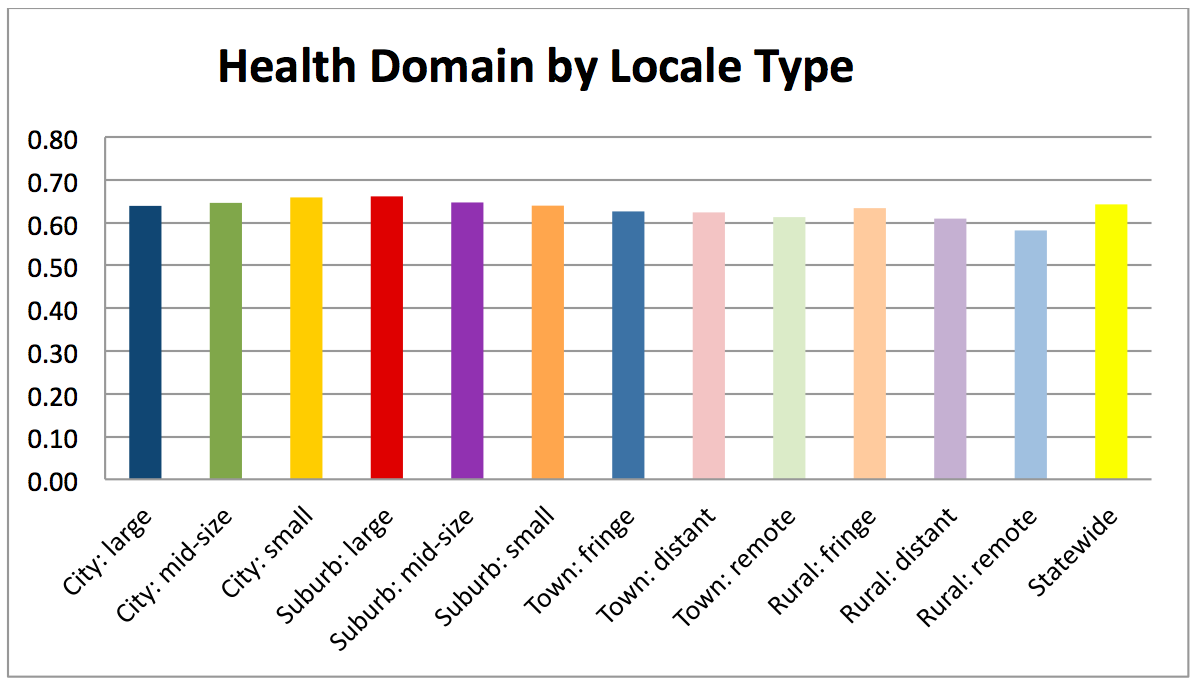
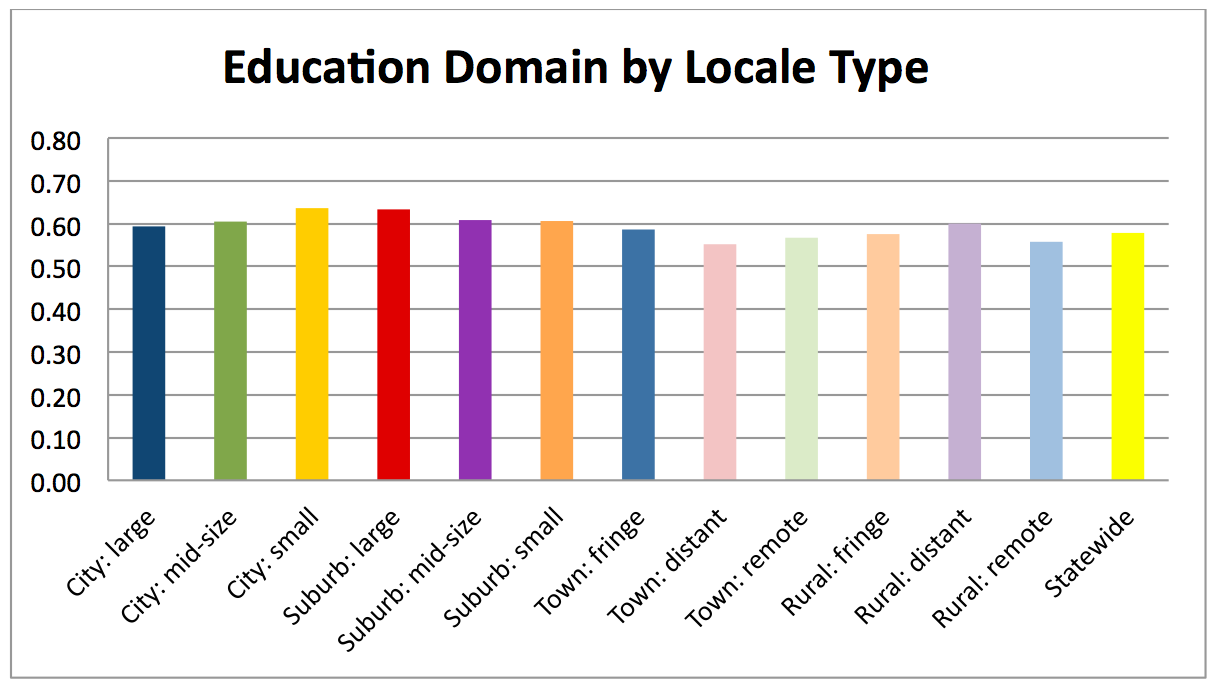
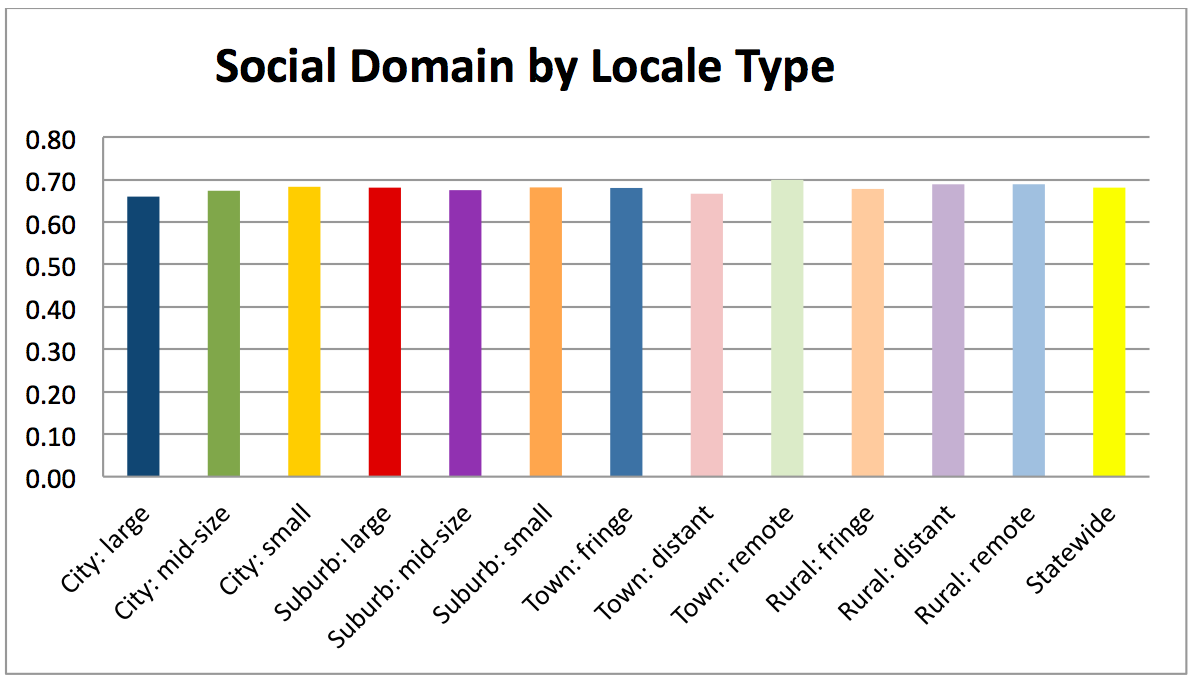
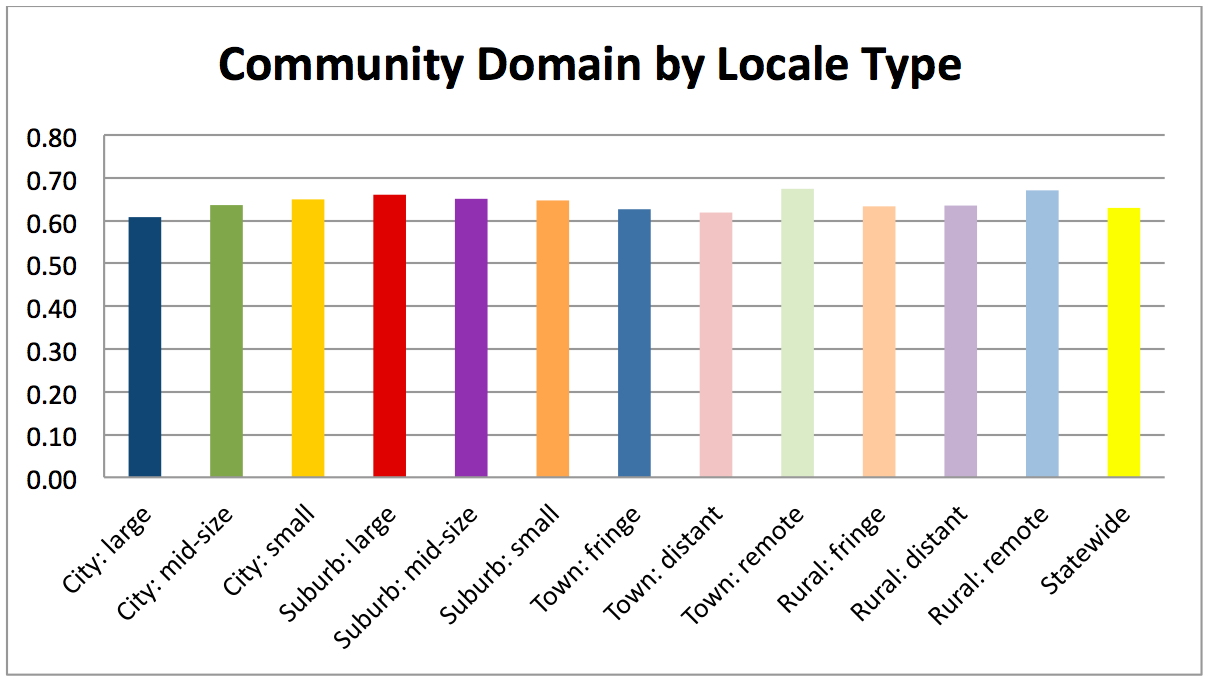
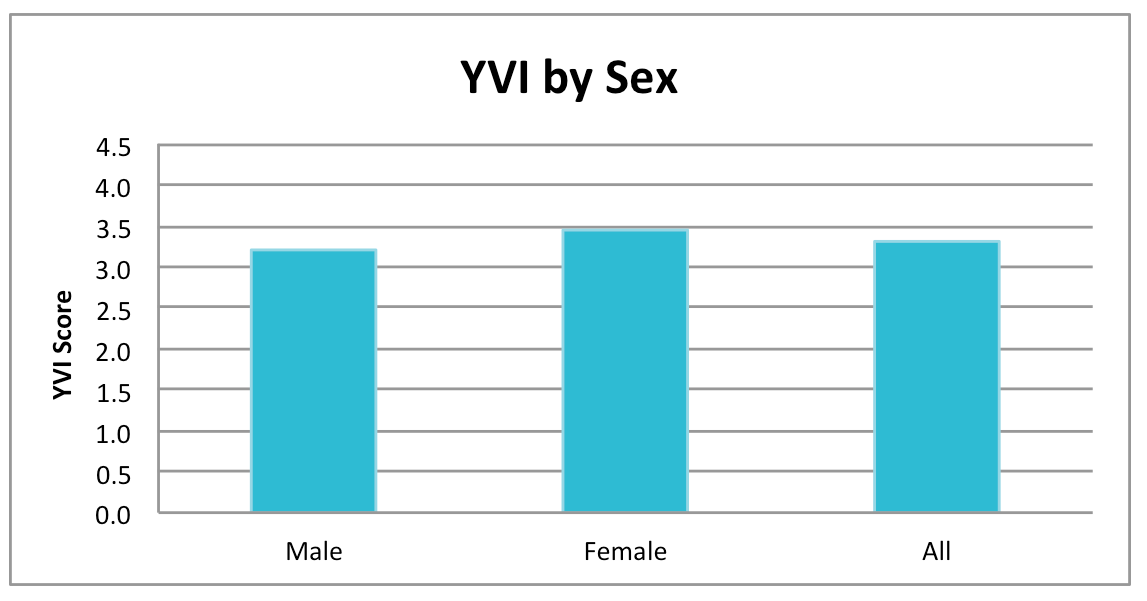
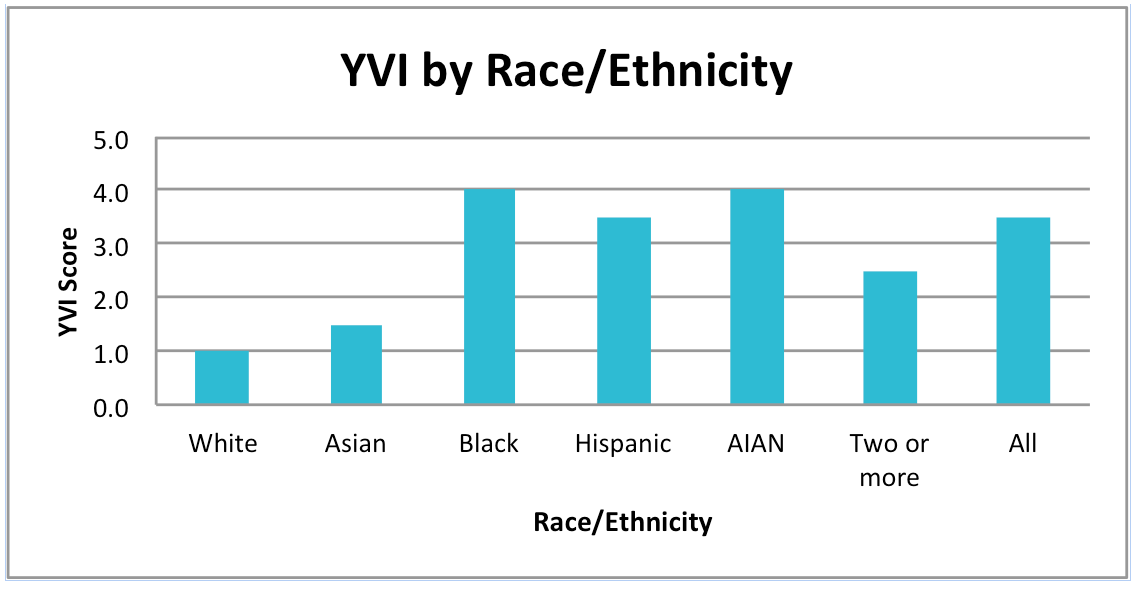
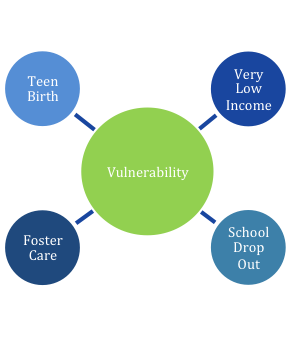
The YVI assesses vulnerability to inadequate support for well-being. It combines four types of data, which we call “indicators,”— the rates
at which youth became teen mothers, did not complete high school, were placed in foster care, and lived in households with very low family incomes. The YVI and related indicator data and maps are available by county for all youth, and by race/ethnicity and sex. Data for three of the four indicators are also provided for all youth across census county divisions (CCDs). These are sub-county regions that include one or more census tracts. Data for the fourth indicator was not available at this level of geography, so we were unable to calculate the YVI for CCDs.
Individual place-based indicator scores
reflect comparison to a benchmark that could be considered
excellent progress. For each indicator
the benchmark is based on the rates experienced by 10% of all
CA youth in the counties with the lowest
rates. Each place receives a “score” for each indicator:
- met the benchmark
- somewhat below benchmark (within 90% of the benchmark)
- below benchmark (between 50-90% of the benchmark)
- far below benchmark (less than 50% of the benchmark)
The YVI averages the four indicator
scores for each county, and highlights places
scoring relatively low (meaning lower
vulnerability rates) and high (meaning higher vulnerability rates)
across the four indicators. In counties where one or more indicators is based on an estimate that is potentially unreliable, the YVI is not calculated. Reliability concerns and thresholds are discussed in more detail below.
Many other conditions are associated
with youth marginalization from potentially key institutional
supports for well-being, including
involvement in the juvenile justice system, teen fatherhood,
identification as LGBTQ, homelessness and
unauthorized immigration status. Unfortunately these data are either
unavailable or unavailable in a form that can easily be mapped for the state at a sub-county level, so we are unable to include them in the index.
New Sub-Group Analysis for YVI
The YVI includes analyses by race, ethnicity and sex wherever there was an adequate population size to do so. At the county level, the YVI and its indicators are now provided for females, males, and populations identified as White, Hispanic/Latino, Black/African American, Asian, Native American/Alaskan Native, and Two or More racial/ethnic backgrounds. Due to small youth populations in many CCDs, subgroups are not analyzed separately at this geographic level. Data are provided for only three of the indicators for CCDs because foster care entry rates are not adequately geo-referenced at the sub-county level. Therefore the YVI is not calculated for CCDs.
To learn more about YVI indicator data,
data sources and their limitations, click the links below.
More On YVI Calculation
To develop benchmarks for each indicator, we adopted an approach employed in health care
research called “Achievable Benchmarks of Care,” or “ABC.” The basic idea is to rank order
all the counties in order of performance on the indicator, and select the 90th percentile
as the benchmark. This would set the benchmark at the level achieved by the county which
performs better than 90% of the other counties. However, this approach can give undue
influence to very small counties, which may not be very representative of the larger
population. The “ABC” approach limits the influence that small places can have on the
benchmark. The steps are as follows:
- First, calculate the performance for each county, adjusting county size to reduce
the impact of smaller units
- rank order the counties by their adjusted performance scores
- beginning with the best-performing county, sequentially add county population until
at least 10% of the total population is included in the sum
- calculate the performance for the subset of counties included in the sum by
aggregating the numerator and denominator counts.
The table below shows a worked example for teen birth rate, based on a total population of 15-19 year old females in California for 2009-11 of 4,072,300.
The table lists a subset of California counties, ordered here by their adjusted teen birth rate, lowest first.
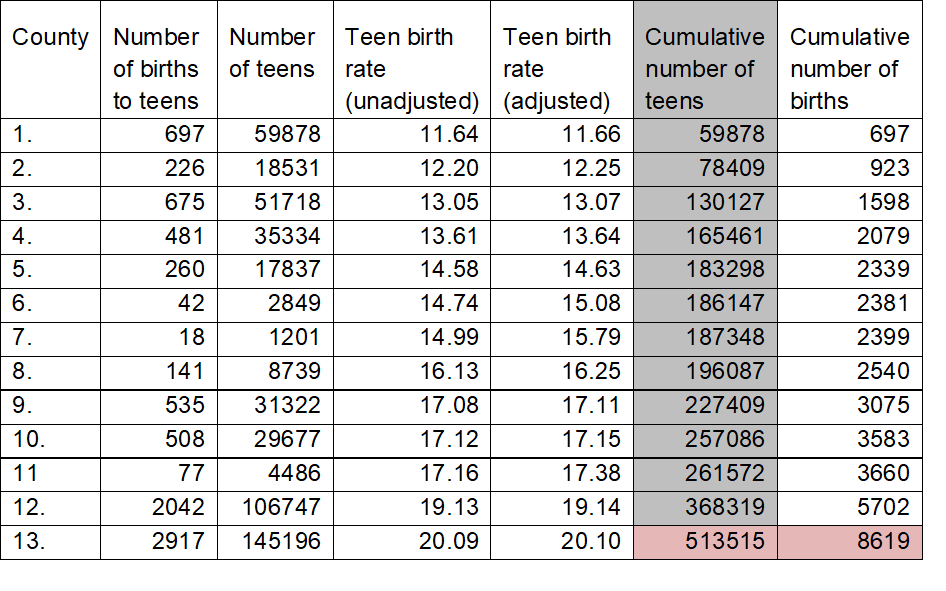
The unadjusted teen birth rate is simply the number of births to teens, divided by the number of teens, multiplied by 1,000. The adjusted teen birth rate is the number of teen births plus one, divided by the number of teens plus two, multiplied by 1,000. This adjustment has little effect in large counties, but does impact the birth rate in smaller counties. Compare the adjusted and unadjusted teen birth rates in rows 7 and 9 to see this.
After the adjusted teen birth rate is calculated, the counties are ordered by the adjusted birth rate, lowest first, as was done in the table above. The cumulative number of female teens, shown in the second to last column, crosses the 10% threshold of 407,230 in the last row, where the cumulative population is 513,515. These 13 counties are used to calculate the teen birth rate using the cumulative totals:
8619 / 513515 * 1000 = 16.78
The “ABC” benchmark for teen birth rate is thus 16.78. Counties have a teen birth rate that is 16.78 or less are given a score of 1 to indicate they met the benchmark. In the example above, counties 1 through 8 would be given a score of 1. The remaining counties, still ordered by their adjusted birth rate, are divided into 4 roughly equal-sized groups, with the first group below the benchmark assigned a score of 2, the next group assigned a score of 3, the third group assigned a score of 4, and the last group assigned a score of 5 indicating that counties in this group are well below the benchmark. The values that separate the groups in the 2010 YVI are used as benchmarks in subsequent years, permitting analysis of change in youth vulnerability over time.
Please see
https://www.ncbi.nlm.nih.gov/pubmed/9828034
and
https://www.ncbi.nlm.nih.gov/pubmed/10461579
for more information.
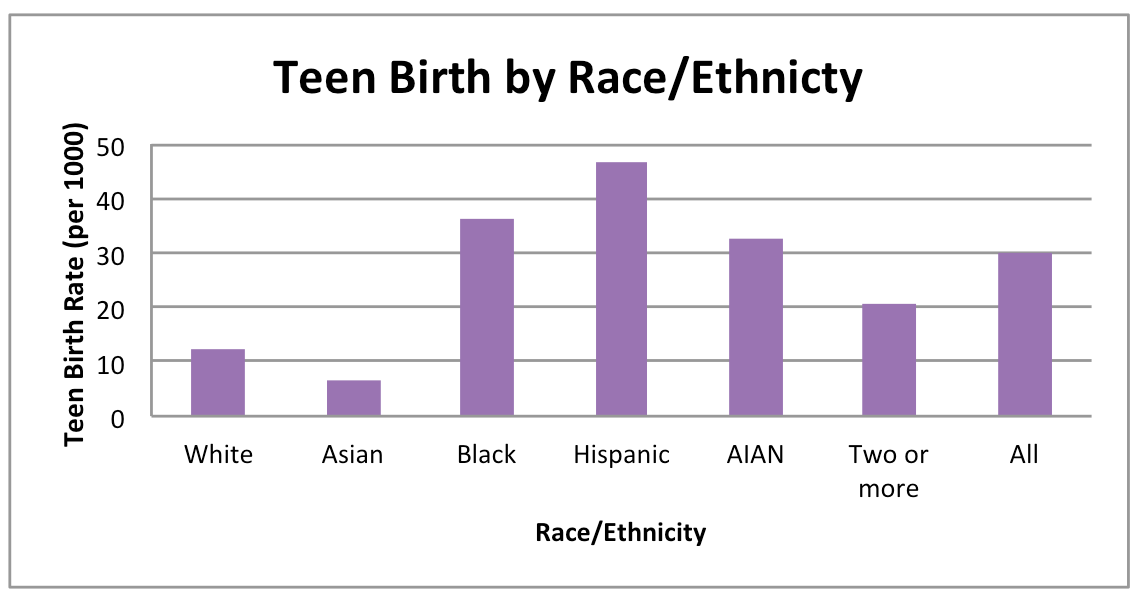
Teen Birth Rate
What do the maps show?
Teen mothers are more likely to not graduate from high school and/or pursue postsecondary education, experience more rapid repeat pregnancy, face the challenges of single parenting and grapple with unemployment and poverty, all of which can result in inadequate support for well-being. Teen Birth Rate maps show the number of births per 1,000 females ages 15-19. It also compares these rates to a benchmark. This benchmark is based on the teen birth rate experienced by 10% of all CA females ages 15-19 in the counties with the lowest teen birth rates. Maps by race/ethnicity are available by county only because the very small numbers of births in many CCDs make subgroup analyses unreliable.
The maps are based on estimates that are subject to uncertainty based on small population sizes or rare events. In places where estimates do not meet a certain threshold of reliability (explained below), we display an asterisk and urge you to interpret these estimates with caution as they are less likely to be accurate.
How did we calculate the teen birth rate?
This teen birth rate map represents the number of 15 to 19 year olds in each area who gave birth during the years 2009-2011, divided by the total number of females in the same age group over the same time period, multiplied by 1,000. Population totals are U.S. Census population estimates for intercensal years.
If a mother’s age or race/ethnic group was not specified, the record was dropped. For the county-level analysis, if the mother’s race was listed as “other,” the record was dropped. We used mother’s county of residence as specified in the birth records to calculate the number of births per county. For CCDs, we used mother’s residential address, geocoded to the census tract, to count the number of births to teen mothers in all census tracts within each CCD. Births that could not be geocoded were excluded (6,133 out of 128,756 births to 15 to 19 year olds, or 4.8%).
The potential for error in the estimated teen birth rate for each location depends primarily on the number of teen births. The number of teen births is expected to follow a Poisson distribution, which expresses the probability that a given number of events will occur within a fixed interval of time and space. Because there is some random temporal and spatial variability in births, the estimated birth rate may vary across geographic units or years, even when the underlying average rate is the same. A statistical measure called margin of error accounts for this naturally occurring variability, and expresses the degree of uncertainty that an estimate is close to the true value. When the margin of error is large relative to the estimate, the estimate is less reliable and should be interpreted with caution. We denote places where the margin of error is 35% the size of the estimate or larger with an asterisk. For a Poisson variable, the margin of error is equal to one divided by the square root of the number of events, multiplied by 1.645. When the number of teen births is 23 or higher, the relative margin of error falls below 35%. Therefore, the estimated birth rate in places with fewer than 23 teen births is considered unreliable and should be used with caution as the true value may differ.
For the purposes of estimating reliability, we assume that the population denominators have no error. “While this assumption is technically correct only for denominators based on the census that occurs every 10 years, the error in intercensal population estimates is usually small, difficult to measure, and therefore not considered.” (National Vital Statistics Reports, Vol. 51, No. 12, August 4, 2003, page 90 https://www.cdc.gov/nchs/data/nvsr/nvsr51/nvsr51_12.pdf).
It should be noted that population estimates for areas or groups with small populations are likely to have more variability, and teen birth estimates in these places should be used with considerable caution.
Where did we get the data?
Teen birth data were obtained (after receiving approval from the Committee for the Protection of Human Subjects) from the California Department of Public Health's Health Information and Research Section, using the Birth Statistical Master Files for 2009-11. County-level female population data came from the U.S. Census postcensal (2009) and intercensal (2010 and 2011) population estimates. Postcensal population estimates are produced by updating the resident population enumerated in a decennial census with estimates of population change (births, deaths, migration) in the years before the next decennial census. Intercensal estimates update the postcensal estimates with information from the next decennial census. We added the population estimates for 2009, 2010, and 2011 to get an estimate of the total number of females ages 15-19 for the race/ethnic groups of interest in each county. Intercensal population estimates are not available for sub-county regions, so we used data from the U.S. Census Bureau’s American Community Survey, table B11001, 5-year estimates for 2011 to get numerator data for the CCD-level teen birth rate indicator. We multiplied the ACS estimate by three to obtain an estimate of the total number of females ages 15 to 19 in in each CCD over the years 2009 to 2011.
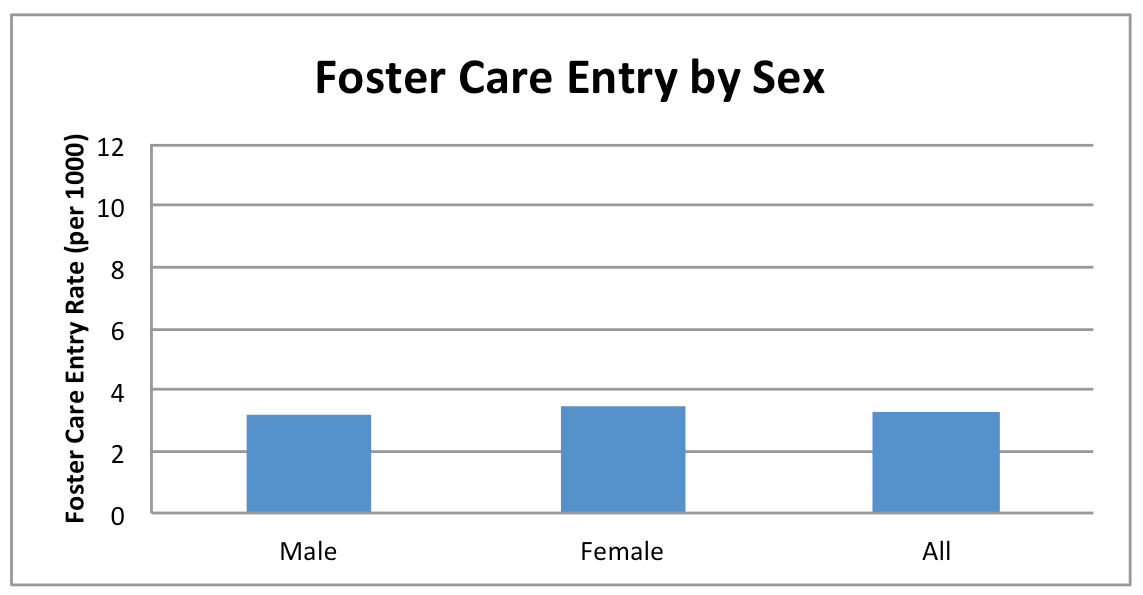
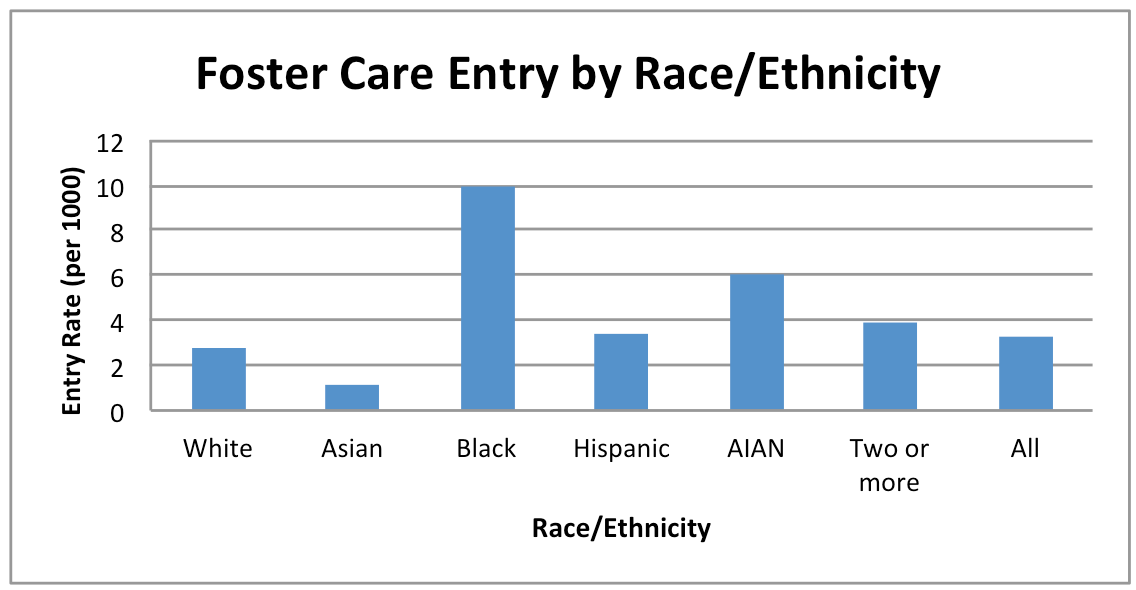
Foster Care Entry Rate
What do the maps show?
Youth who enter the foster care system tend to be vulnerable to inadequate support, which can lead to poor educational, mental and physical health, social developmental and economic outcomes. This map shows foster care entry rates per 1,000 youth age 0 to 17, for the years 2009-11. The map also compares this rate to a benchmark. This benchmark is based on the foster care entry rates experienced 10% of all CA 0-17 year olds in the counties with the lowest rates in 2009-11. Maps and data are available by county only.
The maps are based on estimates that are subject to uncertainty based on small population sizes or rare events. In places where estimates do not meet a certain threshold of reliability (explained below), we display an asterisk and urge you to interpret these estimates with caution as they are less likely to be accurate.
How did we calculate the foster care entry rate?
Foster care entry rates are the number of 0 to 17 year olds in each county who entered foster care between 2009 and 2011, divided by the number of 0-17 year olds in 2009-11, multiplied by 1,000. Foster care data could not be reliably geo-located to sub-county regions, so foster care data are not presented for CCDs.
The potential for unreliability in the foster care entry rate was assessed based on the number of foster care entries. The number of entries is expected to follow a Poisson distribution, which expresses the probability that a given number of events will occur within a fixed interval of time and space. Because there is some random temporal and spatial variability in events, the estimated foster care entry rate may vary across geographic units or years, even when the underlying average rate is the same. A statistical measure called margin of error accounts for this naturally occurring variability, and expresses the degree of uncertainty that an estimate is close to the true value. When the margin of error is large relative to the estimate, the estimate is less reliable and should be interpreted with caution. We denote places where the margin of error is 35% the size of the estimate or larger with an asterisk. For a Poisson variable, the margin of error is equal to one divided by the square root of the number of events, multiplied by 1.645. When the number of foster care entries is 23 or higher, the relative margin of error falls below 35%. Therefore, the estimated foster care entry rate in counties with fewer than 23 foster care entries is considered unreliable and should be used with caution as the true value may differ.
Where did we get the data?
Raw foster care entry data were collected from the Child Welfare Dynamic Reporting System
(https://cssr.berkeley.edu/ucb_childwelfare/GeoData.aspx),
a California Department of Social Services / UC Berkeley collaboration. The use agreement
for these data included non-redistribution of the data. For that reason, we only allow
download of the foster care entry rate rank.
Population estimates were obtained from the CA Department of Finance Demographic Unit, Report P-3: Population Projections by Race/Ethnicity, Detailed Age, and Gender, 2010-2060. (https://www.dof.ca.gov/research/demographic/reports/projections/P-3/, downloaded January 30, 2013).
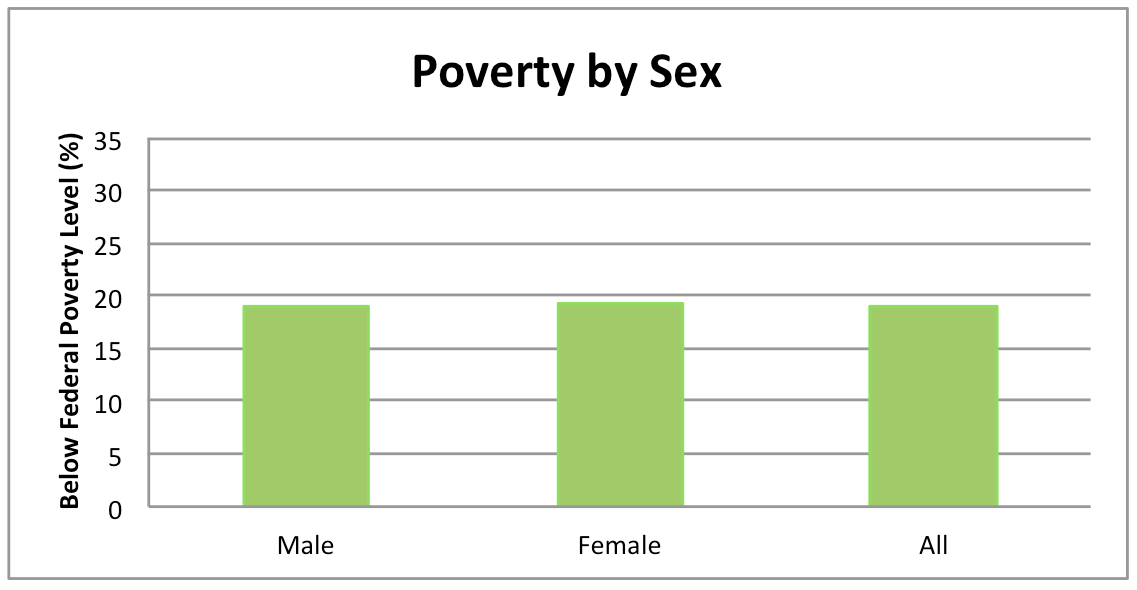
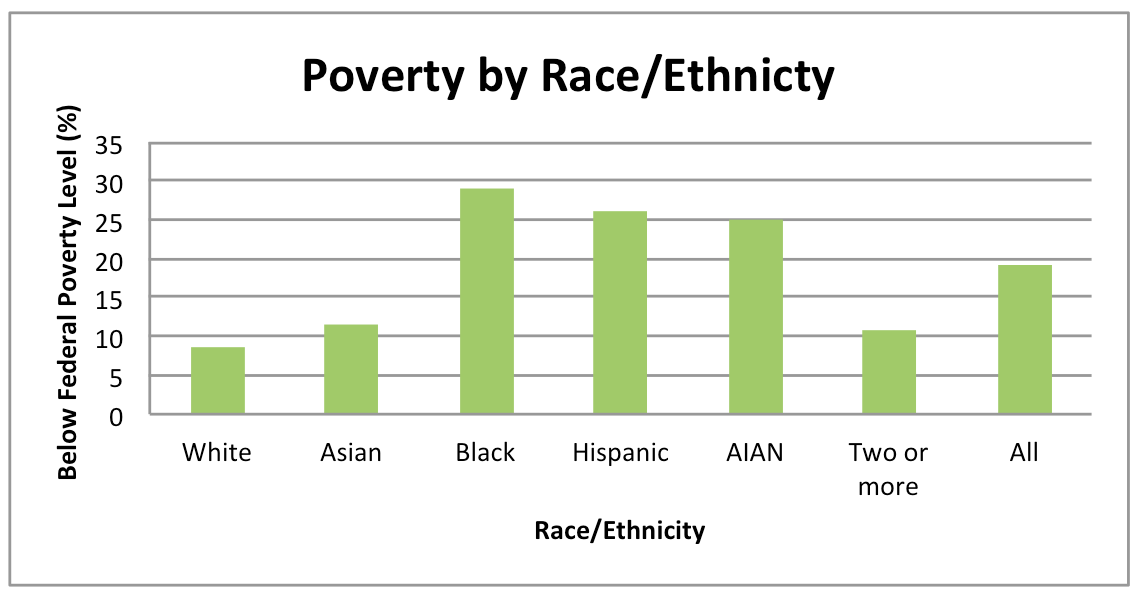
Very Low Income
What do the maps show?
Very low family income is associated with decreased access to support for well-being. This map shows the rates at which 0 to 17 year olds are living in families with incomes that are below the federal poverty level. The map also compares this rate to a benchmark. This benchmark is based on the poverty rates experienced by 10% of all CA 0-17 year olds in the counties with the lowest poverty rates in 2010. Maps are available by sex and race/ethnicity for counties and by CCD.
The maps are based on estimates that are subject to uncertainty based on small population sizes or rare events. In places where estimates do not meet a certain threshold of reliability (explained below), we display an asterisk and urge you to interpret these estimates with caution as they are less likely to be accurate.
How did we calculate very low family income rate?
In this map we show the percentage of 0 to 17 year olds living in families with incomes that are below the federal poverty level. To generate analyses based
on the benchmark, data were collected from the U.S. Census Bureau's American
Community Survey 5-year estimates for 2011, using Table B17001 "Poverty
Status in the Past 12 Months by Sex and Age.” Since the American Community
Survey (ACS) is not a complete census, a margin of error (MOE) for each data
point is given with the raw data. The margin of error is a statistical measure that
represents the degree of uncertainty that a given estimate is close to the true
value being estimated. When the margin of error is large relative to the estimate,
the estimate is less likely to be close to the true value being estimated. We denote
places where the margin of error is 35% the size of the estimate or larger with
an asterisk. Please beware of large MOEs because estimates in these places are less
likely to be accurate and should be interpreted with caution.
Click here for more information about the MOE calculation.
An explanation of the margin of error calculation for aggregated count data and derived proportions is shown here.
Variable list in the ACS report.
| HD01_VD07 | Estimate; Income in the past 12 months below poverty level: - Male: - 12 to 14 years |
| HD02_VD07 | Margin of Error; Income in the past 12 months below poverty level: - Male: - 12 to 14 years |
| HD01_VD08 | Estimate; Income in the past 12 months below poverty level: - Male: - 15 years |
| HD02_VD08 | Margin of Error; Income in the past 12 months below poverty level: - Male: - 15 years |
| HD01_VD09 | Estimate; Income in the past 12 months below poverty level: - Male: - 16 and 17 years |
| HD02_VD09 | Margin of Error; Income in the past 12 months below poverty level: - Male: - 16 and 17 years |
| HD01_VD21 | Estimate; Income in the past 12 months below poverty level: - Female: - 12 to 14 years |
| HD02_VD21 | Margin of Error; Income in the past 12 months below poverty level: - Female: - 12 to 14 years |
| HD01_VD22 | Estimate; Income in the past 12 months below poverty level: - Female: - 15 years |
| HD02_VD22 | Margin of Error; Income in the past 12 months below poverty level: - Female: - 15 years |
| HD01_VD23 | Estimate; Income in the past 12 months below poverty level: - Female: - 16 and 17 years |
| HD02_VD23 | Margin of Error; Income in the past 12 months below poverty level: - Female: - 16 and 17 years |
| HD01_VD36 | Estimate; Income in the past 12 months at or above poverty level: - Male: - 12 to 14 years |
| HD02_VD36 | Margin of Error; Income in the past 12 months at or above poverty level: - Male: - 12 to 14 years |
| HD01_VD37 | Estimate; Income in the past 12 months at or above poverty level: - Male: - 15 years |
| HD02_VD37 | Margin of Error; Income in the past 12 months at or above poverty level: - Male: - 15 years |
| HD01_VD38 | Estimate; Income in the past 12 months at or above poverty level: - Male: - 16 and 17 years |
| HD02_VD38 | Margin of Error; Income in the past 12 months at or above poverty level: - Male: - 16 and 17 years |
| HD01_VD50 | Estimate; Income in the past 12 months at or above poverty level: - Female: - 12 to 14 years |
| HD02_VD50 | Margin of Error; Income in the past 12 months at or above poverty level: - Female: - 12 to 14 years |
| HD01_VD51 | Estimate; Income in the past 12 months at or above poverty level: - Female: - 15 years |
| HD02_VD51 | Margin of Error; Income in the past 12 months at or above poverty level: - Female: - 15 years |
| HD01_VD52 | Estimate; Income in the past 12 months at or above poverty level: - Female: - 16 and 17 years |
| HD02_VD52 | Margin of Error; Income in the past 12 months at or above poverty level: - Female: - 16 and 17 years |
Note that the number ranges
indicate the ratio of poverty status in the past 12 months. When working
with the
margins of error, it is
generally considered best practice to use the fewest number of variables
or components
possible to reduce error.
Section 1. Calculate MOE for Aggregated Numerator.
Step 1.1. Define the MOE for each numerator component estimate.
COMPUTE N1=HD02_VD07.
COMPUTE N2=HD02_VD08.
COMPUTE N3=HD02_VD09.
COMPUTE N4=HD02_VD21.
COMPUTE N5=HD02_VD22.
COMPUTE N6=HD02_VD23.
Step 1.2. Sum the component estimates that comprise the numerator.
COMPUTE X_NUM = HD01_VD07 + HD01_VD88 + HD01_VD09 + HD01_VD21+ HD01_VD22+ HD01_VD23.
The MOE for the numerator is given by MOE_NUM.
Step 1.3. Square the MOE for each numerator component estimate.
Step 1.4. Sum the squared MOEs.
Step 1.5. Take the square root of the sum of the squared MOEs.
COMPUTE MOE_NUM = SQRT((N1^2) + (N2^2) + (N3^2) + (N4^2) + (N5^2) +(N6^2)).
Section 2. Calculate the MOE for the Aggregated Denominator.
Step 2.1. Define the MOE for each denominator component estimate.
COMPUTE D1=HD02_VD07.
COMPUTE D2=HD02_VD08.
COMPUTE D3=HD02_VD09.
COMPUTE D4=HD02_VD21.
COMPUTE D5=HD02_VD22.
COMPUTE D6=HD02_VD23.
COMPUTE D7=HD02_VD36.
COMPUTE D8=HD02_VD37.
COMPUTE D9=HD02_VD38.
COMPUTE D10=HD02_VD50.
COMPUTE D11=HD02_VD51.
COMPUTE D12=HD02_VD52.
Step 2.2. Sum the component estimates that comprise the denominator.
COMPUTE X_DEN = HD01_VD07 + HD01_VD08 + HD01_VD09 + HD01_VD21 + HD01_VD22 + HD01_VD23
+ HD01_VD36 + HD01_VD37 + HD01_VD38 + HD01_VD50 + HD01_VD51 + HD01_VD52.
The MOE for the denominator is given by: MOE_DEN.
Step 2.3. Square the MOE for each numerator component estimate.
Step 2.4. Sum the squared MOEs.
Step 2.5. Take the square root of the sum of the squared MOEs.
COMPUTE MOE_DEN = SQRT((D1^2) + (D2^2) + (D3^2) + (D4^2) + (D5^2) + (D6^2) + (D7^2)
+ (D8^2) + (D9^2) + (D10^2) + (D11^2) + (D12^2)).
Section 3. Calculate the MOE for the Derived Proportion.
The derived ratio is:
COMPUTE R = X_NUM/X_DEN.
The calculation of the MOE is as follows:
Step 3.1. Square the derived proportion.
Step 3.2. Square the MOE of the numerator.
Step 3.3. Square the MOE of the denominator.
Step 3.4. Multiply the squared MOE of the denominator by the squared proportion (R).
Step 3.5. Subtract the results of (3.4) from the squared MOE of the numerator.
Step 3.6. Take the square root of the result of (3.5).
COMPUTE MOE_XNUM = SQRT((MOE_NUM**2) -((R**2)*(MOE_DEN**2))).
Step 3.7. Divide the result of (3.6) by the denominator of the proportion (X_Den).
COMPUTE MOE_X = MOE_XNUM/X_DEN.
Section 4. Define variables for analysis.
Step 4.1. Define MOE of the percentage of 12-17 year olds in the tract who are below 200% of the Federal Poverty Level.
References:
Bidita J. Tithi and Chris Benner, Technical Paper for Vulnerability and Opportunity Indices Calculation, UC Davis, 2011.
Appendix 3 of the US Census
Bureau (October 2008) manual A Compass for Understanding and Using the
American Community Survey Data: What General Data Users Need to
Know.https://www.census.gov/acs/www/guidance_for_data_users/handbooks/
Where did we get the data?
Poverty data come from the U.S. Census Bureau’s American Community Survey table B17001, 5-year estimates.
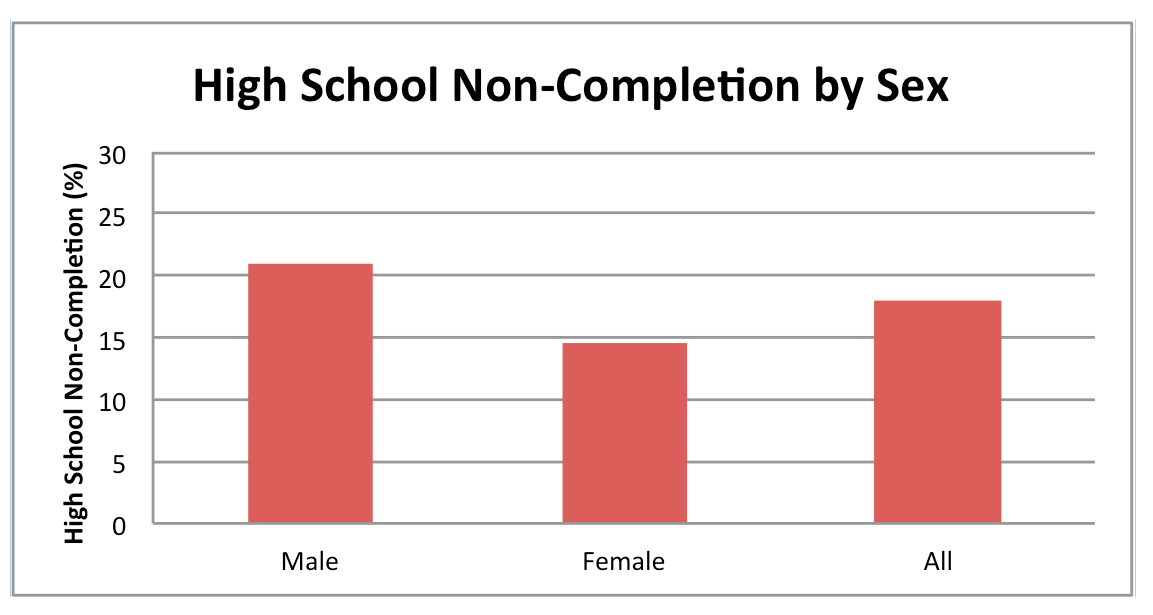
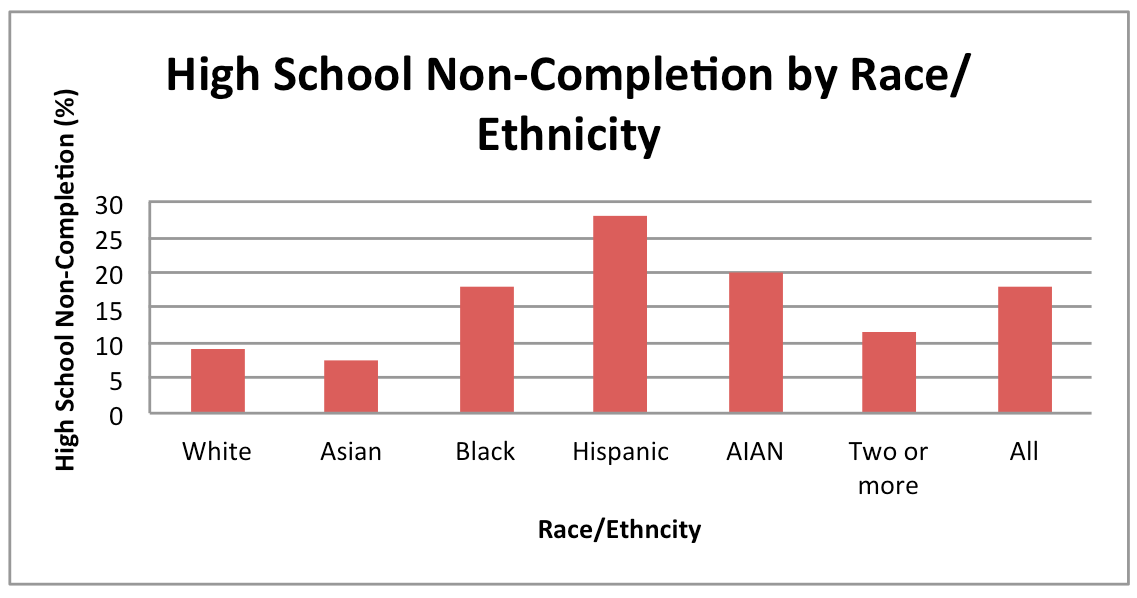
High School Non-Completion (Dropout) Rate
What does this map show?
Youth who do not complete high school are more likely to experience a variety of challenges to their well-being and less access to support. This indicator measures the rates at which young people ages 18 to 24 have less than a 9th grade education or entered 9th to 12th grades but received no diploma. The map also compares this rate to a benchmark. This benchmark is based on the lowest non-completion (or “dropout”) rates experienced by 10% of all CA 18-24 year olds. Data by sex and race/ethnicity are available for counties and by CCD.
The maps are based on estimates that are subject to uncertainty based on small population sizes or rare events. In places where estimates do not meet a certain threshold of reliability (explained below), we display an asterisk and urge you to interpret these estimates with caution as they are less likely to be accurate.
How did we calculate the high school non-completion (dropout) rate?
This indicator was created by dividing the number individuals who did not complete high school by the total population of 18-24 year olds. Data were collected from the U.S. Census Bureau's American Community Survey 5-year estimates for 2007-11, using Table B15001, "Sex by Age by Educational Attainment for the Population 18 years and Over."
Since the American Community Survey (ACS) is not a complete census, a margin of error (MOE) for each data point is given with the raw data. The margin of error is a statistical measure that represents the degree of uncertainty that a given estimate is close to the true value being estimated. When the margin of error is large relative to the estimate, the estimate is less likely to be close to the true value being estimated. We denote places where the margin of error is 35% the size of the estimate or larger with an asterisk. Please beware of large MOEs because estimates in these places are less likely to be accurate and should be interpreted with caution.
Click here for more information
Here we provide an explanation of the margin of error calculation for aggregated count data and derived proportions.
Variable list in the ACS report
| HD01_VD01 | 'Total:' |
| HD01_VD02 | 'Total Male:' |
| HD01_VD03 | 'Total: Male: 18 to 24 years:' |
| HD01_VD04 | 'Total: Male: 18 to 24 years: Less than 9th grade' |
| HD01_VD05 | 'Total: Male: 18 to 24 years: 9th to 12th grade, no diploma' |
| HD01_VD43 | 'Total: Female:' |
| HD01_VD44 | 'Total: Female: 18 to 24 years:' |
| HD01_VD45 | 'Total: Female: 18 to 24 years: Less than 9th grade' |
| HD01_VD46 | 'Total: Female: 18 to 24 years: 9th to 12th grade, no diploma' |
| HD02_VD01 | 'Total: (MOE)' |
| HD02_VD02 | 'Total: Male: (MOE)' |
| HD02_VD03 | 'Total: Male: 18 to 24 years: (MOE)' |
| HD02_VD04 | 'Total: Male: 18 to 24 years: Less than 9th grade (MOE)' |
| HD02_VD05 | 'Total: Male: 18 to 24 years: 9th to 12th grade, no diploma (MOE)' |
| HD02_VD43 | 'Total: Female: (MOE)' |
| HD02_VD44 | 'Total: Female: 18 to 24 years: (MOE)' |
| HD02_VD45 | 'Total: Female: 18 to 24 years: Less than 9th grade (MOE)' |
| HD02_VD46 | 'Total: Female: 18 to 24 years: 9th to 12th grade, no diploma (MOE)'. |
PURPOSE: Calculating the MOE
for the Percentage of 18-24 year olds who completed either less than 9th
grade, or 9th through 12th grade, without receiving a diploma.
Section 1. Calculate MOE for Aggregated Numerator.
Step 1.1. Define the MOE for each numerator component estimate.
COMPUTE N1=HD02_VD04.
COMPUTE N2= HD02_VD05.
COMPUTE N3= HD02_VD45.
COMPUTE N4= HD02_VD46.
Step 1.2. Sum the component estimates that comprise the numerator.
COMPUTE X_NUM = HD01_VD04 + HD01_VD05 + HD01_VD45 + HD01_VD46.
The MOE for the numerator is given by MOE_NUM.
Step 1.3. Square the MOE for each numerator component estimate.
Step 1.4. Sum the squared MOEs.
Step 1.5. Take the square root of the sum of the squared MOEs.
COMPUTE MOE_NUM = SQRT((N1^2) + (N2^2) + (N3^2) + (N4^2)).
Section 2. Calculate the MOE for the Aggregated Denominator.
Step 2.1. Define the MOE for each denominator component estimate.
COMPUTE D1= HD02_VD03.
COMPUTE D2= HD02_VD44.
Step 2.2. Sum the component estimates that comprise the denominator.
COMPUTE X_DEN = (HD01_VD03+HD01_VD44).
The MOE for the denominator is given by: MOE_DEN.
Step 2.3. Square the MOE for each numerator component estimate.
Step 2.4. Sum the squared MOEs.
Step 2.5. Take the square root of the sum of the squared MOEs.
COMPUTE MOE_DEN = SQRT((D1^2) + (D2^2)).
Section 3. Calculate the MOE for the Derived Proportion.
The derived ratio is:
COMPUTE R = X_NUM/X_DEN.
The calculation of the MOE is as follows:
Step 3.1. Square the derived proportion.
Step 3.2. Square the MOE of the numerator.
Step 3.3. Square the MOE of the denominator.
Step 3.4. Multiply the squared MOE of the denominator by the squared proportion (R).
Step 3.5. Subtract the results of (3.4) from the squared MOE of the numerator.
Step 3.6. Take the square root of the result of (3.5).
COMPUTE MOE_XNUM = SQRT((MOE_NUM^2) -((R^2)*(MOE_DEN^2))).
Step 3.7. Divide the result of (3.6) by the denominator of the proportion (X_Den).
COMPUTE MOE_X = MOE_XNUM/X_DEN.
Section 4. Define variables for analysis.
Step 4.1. Define MOE of the
Percentage of 18-24 year olds in the tract who (1) completed less than
9th grade OR (2) completed 9th-12th grade without receiving a diploma.
COMPUTE M_P1824_Dropouts= MOE_X.
Step 4.2. Define percentage
of 18-24 year olds in the tract who (1) completed less than 9th grade OR
(2) completed 9th-12th grade without receiving a diploma.
COMPUTE P1824_Dropouts = R.
References:
Bidita J. Tithi and Chris Benner, Technical Paper for Vulnerability and Opportunity Indices Calculation, UC Davis, 2011.
Appendix 3 of the US Census
Bureau (October 2008) manual A Compass for Understanding and Using the
American Community Survey Data: What General Data Users Need to
Know.https://www.census.gov/acs/www/guidance_for_data_users/handbooks/
Where did we get the data?
To search the U.S. Census website
for data, please see the American Fact Finder query tool at:
https://factfinder2.census.gov/faces/nav/jsf/pages/index.xhtml.